US-ATLAS Shared Tier-3's
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What computing resources does US-ATLAS offer?
Objectives
Understand what US-ATLAS provides.
In this episode, we’ll introduce the concept of a “Shared Tier-3”, and how you can use it.
Computing Centers in ATLAS
ATLAS has “tiered” computing facilities:
- Tier-0: CERN-hosted resources that perform first-pass processing of detector data. Used for calibrations and initial event reconstruction. Users do not run jobs here.
- Tier-1: Several Tier-1’s located throughout the world; in the US, we have a Tier-1 at Brookhaven National Lab. Large facilities used for grid computing. Used for both production jobs and user jobs. No interactive access for users.
- Tier-2: Many Tier-2’s located throughout the world, several in the US. From the user point of view, these are indistinguishable from Tier-1’s.
- Tier-3: Equivalent of institutional clusters. Users need to be granted permission to access them. They provide interactive access in addition to local batch clusters and storage. (Similar to
lxplusat CERN.)
Our focus will be on the Tier-3’s, which are most effectively used for processing flat ntuples:

In the US, a lot of institutions have mini-clusters with access restricted to institutional users. These were especially common in the early days of ATLAS, but as that hardware aged, the facilities became increasingly challenging to maintain and grow to support the needs of today’s analyzers.
In response to this, US-ATLAS has set up three shared facilities, where any US-ATLAS user can get access to computing resources that go well beyond what a single institute would commonly provide. All shared tier-3’s include (or will include):
- Interactve login nodes for software development
- ATLAS software available via
setupATLAS - Access to at least 1000 CPU cores per site in a batch system
- Access to large amounts of local storage
- Access to GPU’s
- Jupyter notebook support
The University of Chicago Shared Tier-3 is the Analysis Facility we’re using for this bootcamp, so you should already have access to a Shared tier-3!
Shared Tier-3’s in the US
There are two other shared tier-3 facilities in the US: one at SLAC National Laboratory, the other at Brookhaven National Laboratory.
- The BNL Tier-3 is part of a larger computing facility at the SDCC at BNL.
– ATLAS has priority for approximately 2000 cores available in a condor queue
— If the rest of the facility has free slots, then ATLAS jobs can spill over into an additional >30k cores
– Users have access to 500 GB of disk space, plus an additional 5 TB of dCache space
– Interactive logins via shells
– Jupyter Notebooks: https://jupyter.sdcc.bnl.gov/
— More available as part of a shared filesystem (
pnfs) for group work - The SLAC Tier-3 is also part of a shared pool at SLAC – ATLAS has priority for ~1200 cores, potential access up to 15k cores – 100 GB home space plus 2-10 TB for data – Interactive logins via shells – Jupyter Notebooks: https://sdf.slac.stanford.edu/public/doc
Both facilities also allow users to access to GPU’s for machine learning and likelihood fits.
It can take some time (weeks or months) to complete all the necessary steps to register at BNL or SLAC. Suggest that you start now, and get the accounts before you think you might need them!
For more details, see the US-ATLAS Shared Tier-3 documentation.
Key Points
US-ATLAS can’t do your analysis, but it can help.
LOCALGROUPDISK
Overview
Teaching: 10 min
Exercises: 10 minQuestions
How can I store my grid outputs?
Objectives
Learn how to use LOCALGROUPDISKs.
LOCALGROUPDISK overview
ATLAS provides grid storage in a number of different flavors
DATADISK: this is disk space reserved for official ATLAS samples, either data or MC.SCRATCHDISK: when you run grid jobs, often the outputs will be stored on aSCRATCHDISKat the site your jobs ran. Data on these disks are deleted regularly (every week or two)LOCALGROUPDISK: national or institutional resources that are restricted to users with the appropriate VOMS role assigned to their grid certificate.- … and others!
For many people, their grid computing model is to:
- Submit jobs to the grid
- When jobs are done, download them to local computing resources (or eos, etc) using
rucio get - Not be concerned when the grid copies of their data are deleted
However, if the dataset is large, or shared with many people, it can be advantageous to move the data using R2D2 rules instead of rucio get, and to host a single copy rather than requiring everyone to download their own copy. This is where US-ATLAS LOCALGROUPDISKs come in!
If you have the /atlas/usatlas role assigned to your grid certificate, you can store your data on any US LOCALGROUPDISK. Currently the quota for any user is 15 TB on a single LOCALGROUPDISK, or slightly more if the data are spread across several. There’s lots of available space in the disks:

So, for example, there are LOCALGROUPDISKs attached to BNL, SLAC, and MWT2, which are all co-located with our shared Tier-3 facilities, making either direct access or access via xrootd fairly easy. (See documentation on the shared tier-3’s for site-specific instructions to access data on the associated LOCALGROUPDISK.)
Getting the /atlas/usatlas role
Go to the LCG VOMS page:
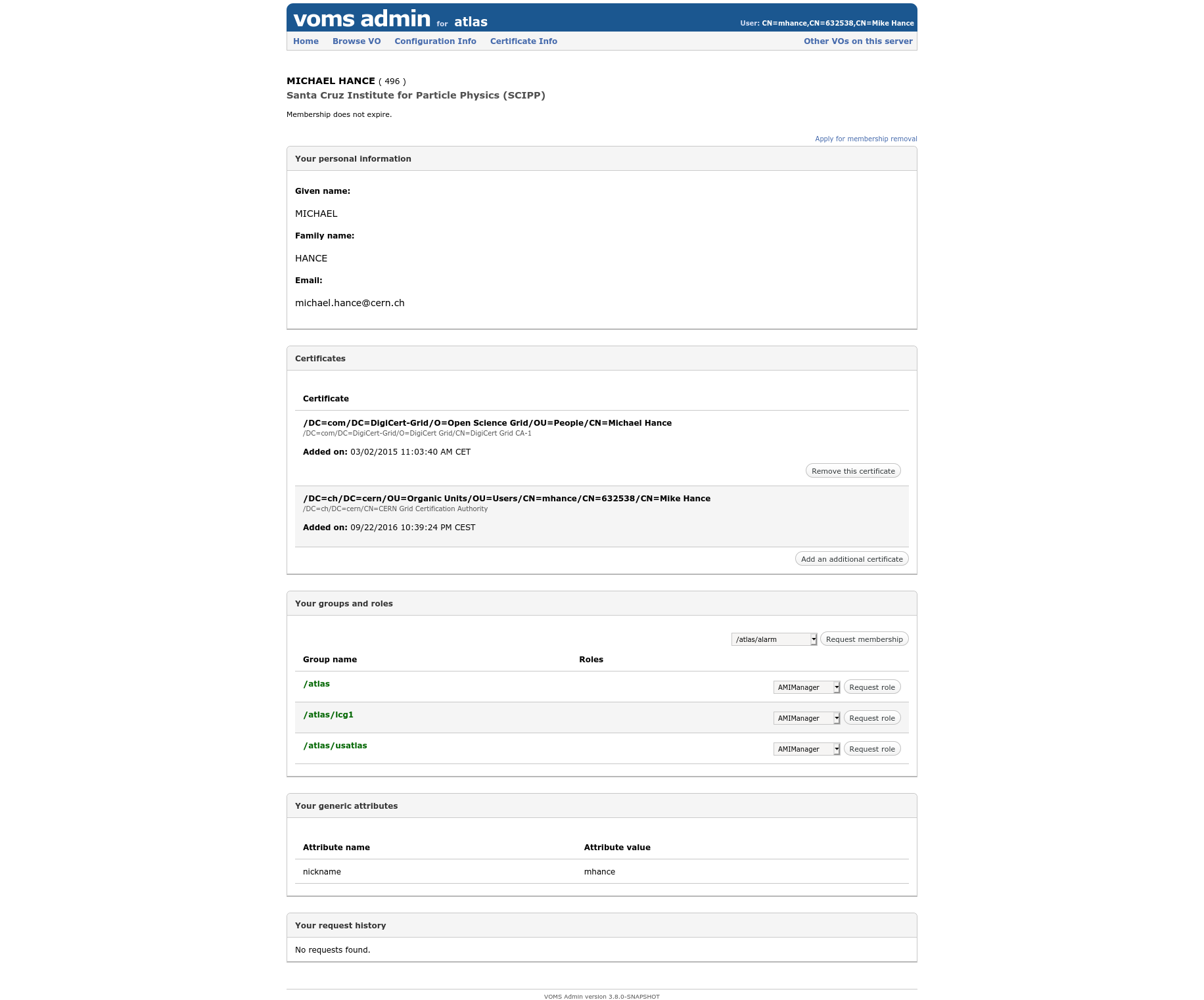
In the “Your groups and roles” section, request membership for the /atlas/usatlas role. It may take a few days to be approved, but once it is then you have access to grid storage in the US! This means you can store your datasets in US LOCALGROUPDISK endpoints. This is nice, because:
- otherwise your user data on the grid will be deleted fairly soon after you make it (on the assumption that you’ve downloaded it to local storage already). On the other hand, if it’s in a LOCALGROUPDISK, it never expires! (It is a shared resource though, so we will ask you to clean up unused data sets after a while.)
- the Shared Tier-3’s can read data directly from their own LOCALGROUPDISKs, without needing to download the data manually.
Moving data into the LOCALGROUPDISK
Once you have that role, the next step is to request that your favorite datasets be replicated on a LOCALGROUPDISK. Navigate to the R2D2 page: https://rucio-ui.cern.ch/r2d2
-
Log in with your X509 certificate:
-
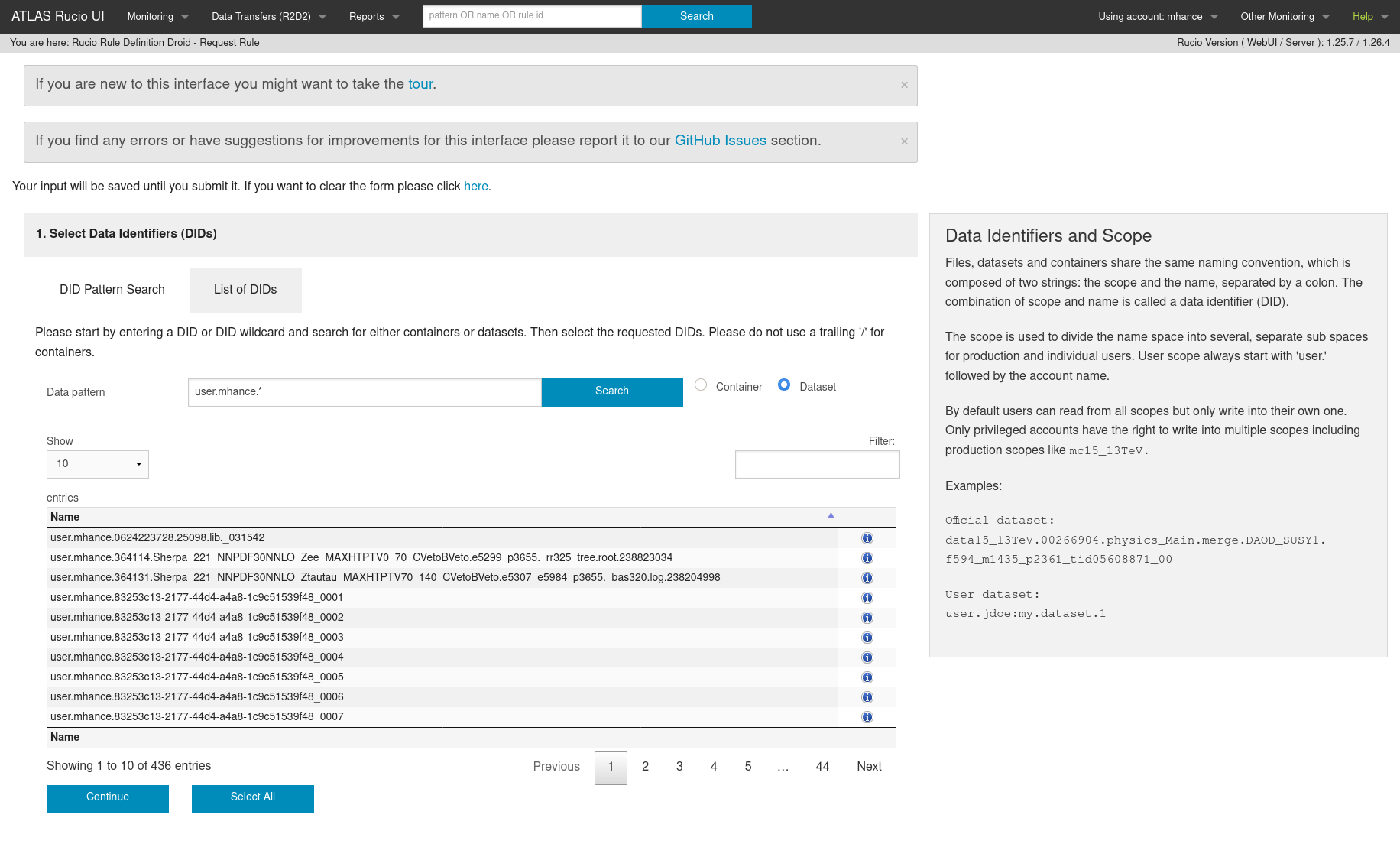
Find the datasets you’d like to replicate.
-
Choose which LOCALGROUPDISK you want to use. –
BNL-OSG2_LOCALGROUPDISKis the right endpoint for BNL.BNL-OSG2_SCRATCHDISKcan be used if you only need the data to be there for a few days or a week. –SLACXRD_DATADISK,SLACXRD_LOCALGROUPDISKandSLACXRD_SCRATCHDISKare all possible endpoints for SLAC.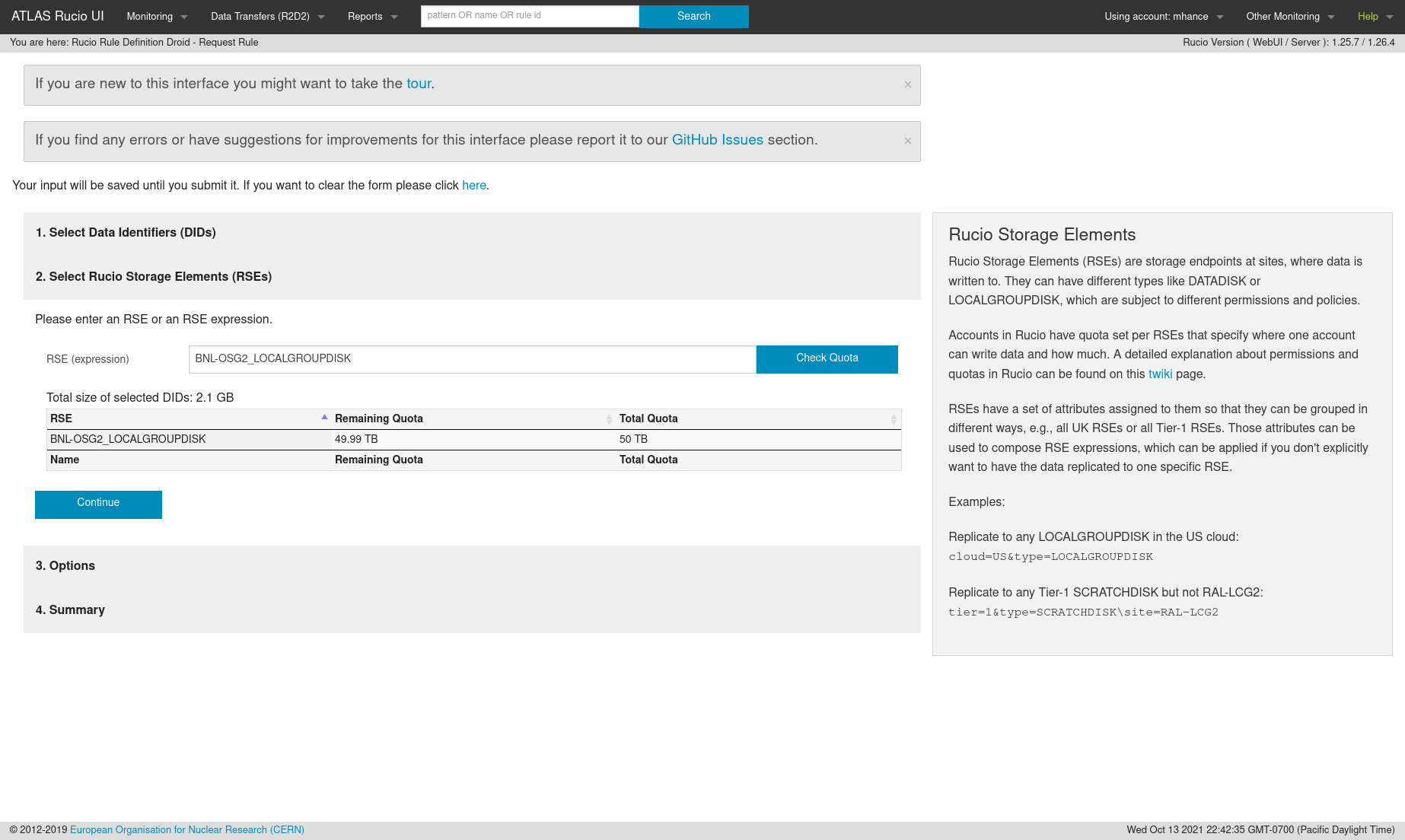
-
Make sure to set the lifetime – leave blank for data that shouldn’t expire!
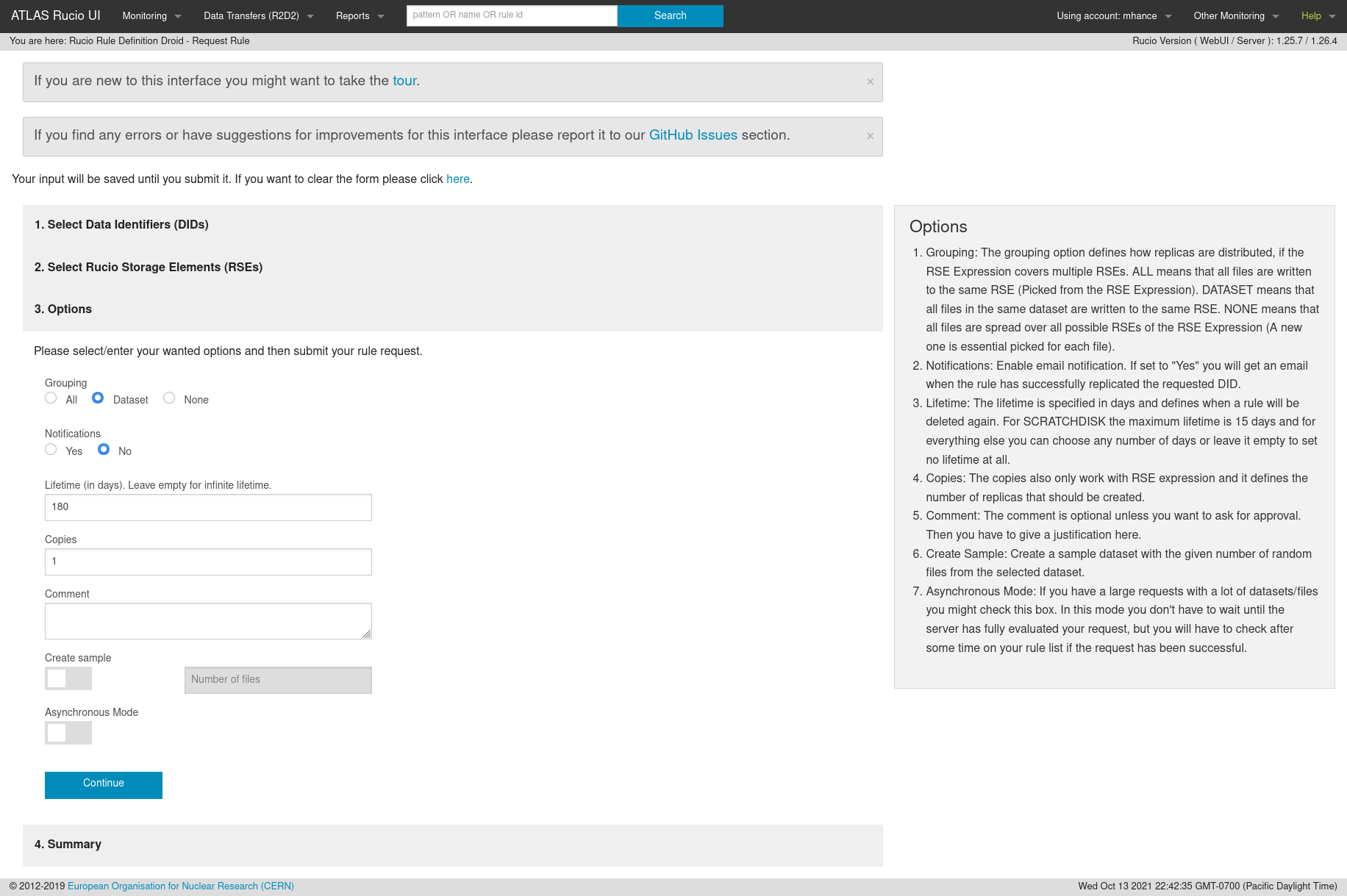
-
Submit your request
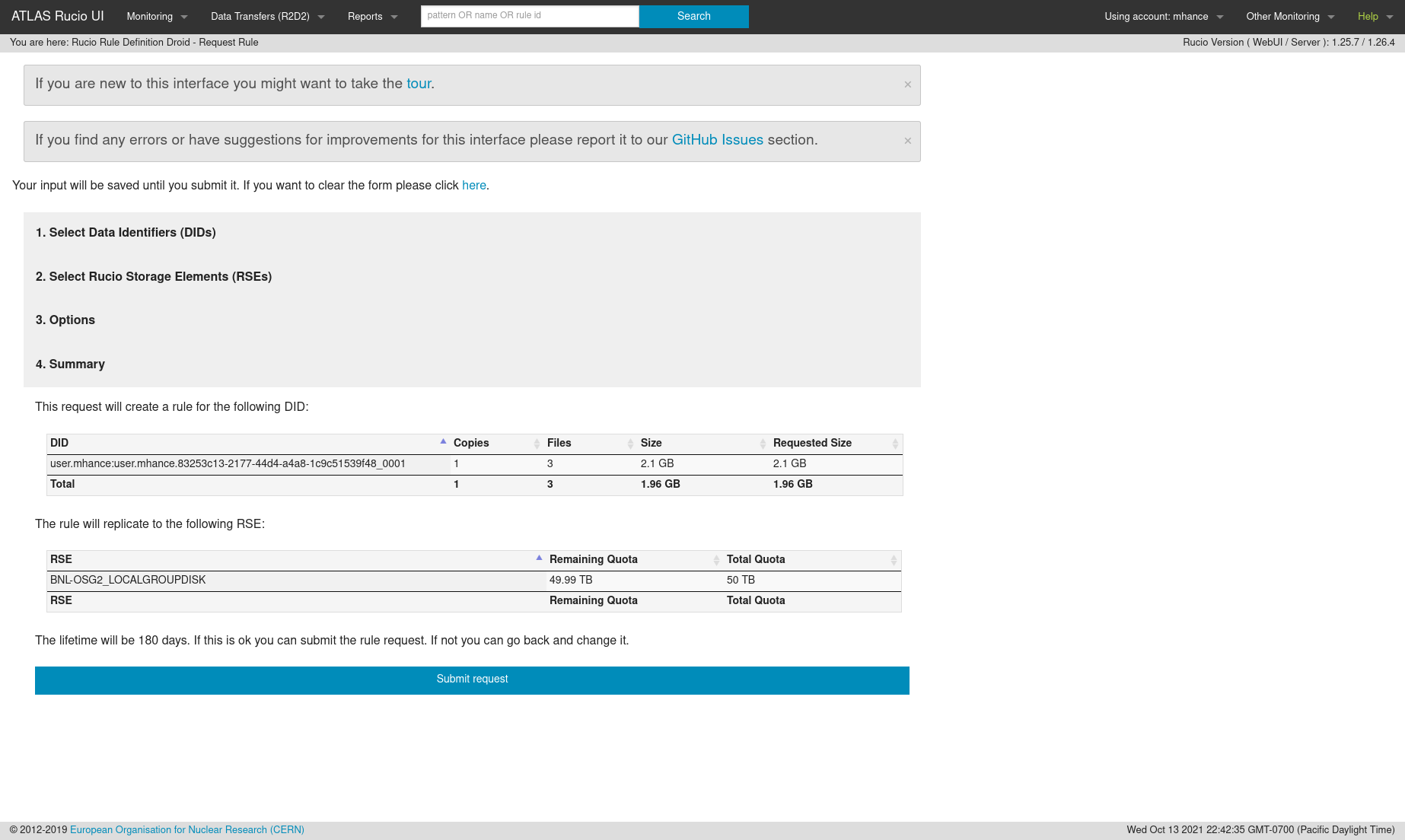
-
… and now the rule exists! It may take a day or so for the transfer to occur, depending on how big the dataset is.

Getting more space
If you need more space on the LOCALGROUPDISK at your facility, or just need more space in general for a short period of time, you can request a temporary increase in your allocation at https://atlas-lgdm.cern.ch/LocalDisk_Usage/USER/RequestFormUsage/.
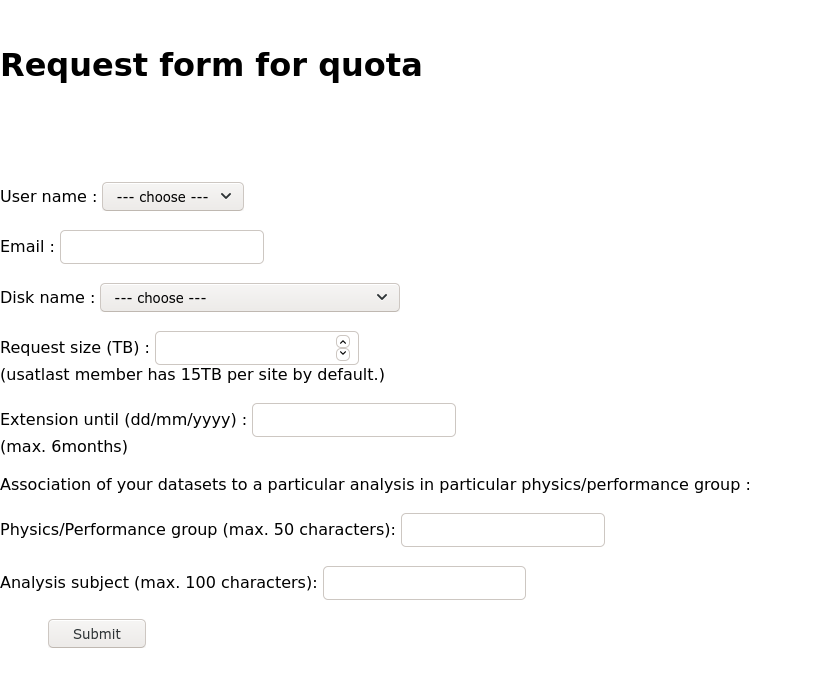
Note that the increase in space is expected to be temporary, and we will come back to ask you to clean up once the extension period has passed!
Key Points
With the proper grid roles, you can use US disk storage for your rucio datasets.
Other Resources
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What other services can I use?
Objectives
Learn how to use more experimental or specialized resources.
Amazon EC2 analysis facility
A collaboration between the California State University system and Amazon has enabled ATLAS users to use Amazon EC2 resources for analysis work. You can run jobs as though the EC2 resources were like a grid site, or treat it like a Tier-3 and run a scalable “local” analysis. More info is available in some recent summary slides. If you are interested, there are setup instructions here. Please contact Harinder Singh Bawa harinder.singh.bawa@gmail.com for more details.
Another collaboration between US-ATLAS and Google is exploring the use of Google resources for ATLAS analysis projects. The project was explained in more depth at a recent Technical Interchange Meeting. If you are interested in participating here, contact Kaushik De kaushik@uta.edu and Alexei Klimentov alexei.klimentov@cern.ch, briefly describing what you want to do, how much resource (CPU time, storage) you need, and what kind of software you’ll be running.
Key Points
Traditional and non-traditional computing models welcome!